Yolo Dataset을 이용해서 Segmentation Dataset으로 만들기 위한 과정에 대한 설명입니다.
우선 Facebook의 공식 git 코드를 참조하였습니다 링크는 아래와 같습니다.
https://github.com/facebookresearch/segment-anything/blob/main/notebooks/predictor_example.ipynb
segment-anything/notebooks/predictor_example.ipynb at main · facebookresearch/segment-anything
The repository provides code for running inference with the SegmentAnything Model (SAM), links for downloading the trained model checkpoints, and example notebooks that show how to use the model. -...
github.com
우선 진행해야하는 순서는
1. SAM에 Yolo의 Box Label을 이용해서 segmentation mask 생성
2. Mask의 polygon을 추출
3. 추출한 polygon을 데이터셋으로 제작
이 있습니다.
1. SAM에 Yolo의 Box Label을 이용해서 segmentation mask 생성
우선 주어진 Yolo 데이터 셋이 있다는 가정하에 아래 코드를 이용하면 SAM의 입력 프롬프트로 Box 값을 넣을 수 있습니다.
import numpy as np
import torch
import numpy as np
import matplotlib.pyplot as plt
import cv2
import sys
import os
from matplotlib import pyplot as plt
# 시각화를 위한 함수 선언
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30/255, 144/255, 255/255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels==1]
neg_points = coords[labels==0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0,0,0,0), lw=2))
# SAM 모델 Load
sys.path.append("..")
from segment_anything import sam_model_registry, SamPredictor
# pth 파일은 hugging face에서 다운로드 가능합니다
sam_checkpoint = "sam_vit_h_4b8939.pth"
model_type = "vit_h"
device = "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)
# 이미지와 label 위치 지정
image_dir = ""
label_dir = ""
# 이미지 파일의 이름 가져오기
image_files = [f for f in os.listdir(image_dir) if f.endswith('.jpg')]
# 반복문을 통해 이미지 파일과 label 파일의 정보 SAM에 넣기
for i, image_file in enumerate(image_files):
# 매 이미지 마다 list 초기화
input_boxes = []
image_path = os.path.join(image_dir, image_file)
label_file = os.path.splitext(image_file)[0] + ".txt"
label_path = os.path.join(label_dir, label_file)
if os.path.exists(label_path):
image = cv2.imread(image_path)
height, width, _ = image.shape
predictor.set_image(image)
with open(label_path, 'r') as f:
for line in f.readlines():
# label 정보를 이용해 class_id와 박스 추출(좌상단 & 우하단 값)
class_id, x_center, y_center, box_width, box_height = map(float, line.strip().split())
x_center *= width
y_center *= height
box_width *= width
box_height *= height
x_min = int(x_center - (box_width / 2))
y_min = int(y_center - (box_height / 2))
x_max = int(x_center + (box_width / 2))
y_max = int(y_center + (box_height / 2))
input_boxes.append([x_min, y_min, x_max, y_max])
input_boxes_tensor = torch.tensor(input_boxes, dtype=torch.float, device='cuda')
transformed_boxes = predictor.transform.apply_boxes_torch(input_boxes_tensor, image.shape[:2])
# 박스 내부의 객체 mask 추출
masks, _, _ = predictor.predict_torch(
point_coords=None,
point_labels=None,
boxes=transformed_boxes,
multimask_output=False,
)
# 출력값 시각화
for mask in masks:
show_mask(mask.cpu().numpy(), plt.gca(), random_color=True)
for box in input_boxes_tensor:
show_box(box.cpu().numpy(), plt.gca())
else:
not_found.append(label_path)
결과 이미지는 아래와 같습니다. 박스 정보를 통해 성공적으로 mask를 찾은 것을 볼 수 있습니다!!


2. Mask의 polygon을 추출
mask를 이용해서 polygon을 추출하는 방법으로 measure.find_contours() 함수를 사용했습니다. 추가된 코드는 아래와 같습니다.
(contour의 출력이 y,x 순으로 출력되는데 x,y로 생각해서 폴리곤이 계속 회전되어있는 문제가...)
for mask, box in zip(masks, input_boxes):
# bool => float(출력되는 형태가 bool이기에 float로 변환)
mask_float = mask.cpu().numpy().astype(np.float32)[0]
contours = measure.find_contours(mask_float, 0.5)
for contour in contours:
# 마스크 polygon 좌표 추출
polygon = Polygon([(x, y) for y, x in contour])
# 가장 작은 박스의 1/10 사이즈 보다 작은 mask는 삭제 (티클 제거를 위해)
if polygon.is_valid and polygon.area > smallest_area / 10:
# contour의 출력이 y,x 순서로 되어 있기에 x,y 순서로 변경
scaled_coords = [(int(x), int(y)) for y, x in contour]
# 시각화 코드: 폴리곤을 빨간색으로 그리기
x_coords, y_coords = zip(*scaled_coords) # x, y 좌표 분리
plt.plot(x_coords, y_coords, color='r', lw=2) # 빨간색 선으로 윤곽선 시각화
위와 같이 출력되는 Polygon의 노이즈를 줄이고 시각화를 한 결과는 아래와 같습니다.
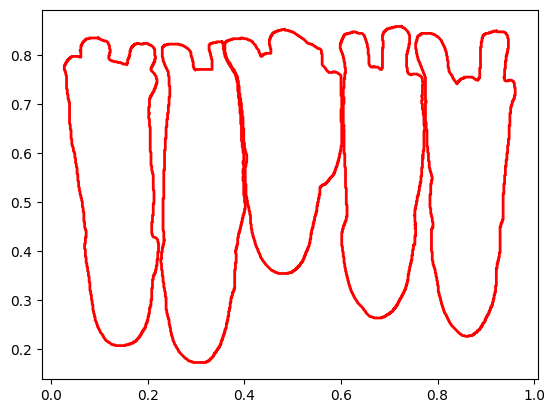
어라? 이상합니다?
강아지의 polygon은 잘 나온 것 같은데 시각화 결과가 뒤집어져 있습니다....
왜 그런걸까요??
이유는 좌표에 있습니다!!!!
보통 이미지에서 좌표의 원점은 왼쪽 상단에 있습니다. 하지만 위 사진을 보면 원점이 왼쪽 하단에 있습니다. 따라서 좌표는 잘 뽑았으나 시각화에 문제가 있었습니다... 강조하는 이유는 제가 이것 때문에 시간을 많이 빼았겼기 때문... ㅠㅠ
따라서 시각화 할 때 원점을 왼쪽 상단으로 한다면 아래와 같이 결과가 잘 나타납니다.
for mask, box in zip(masks, input_boxes):
# bool => float(출력되는 형태가 bool이기에 float로 변환)
mask_float = mask.cpu().numpy().astype(np.float32)[0]
contours = measure.find_contours(mask_float, 0.5)
for contour in contours:
# 마스크 polygon 좌표 추출
polygon = Polygon([(x, y) for y, x in contour])
# 가장 작은 박스의 1/10 사이즈 보다 작은 mask는 삭제 (티클 제거를 위해)
if polygon.is_valid and polygon.area > smallest_area / 10:
# contour의 출력이 y,x 순서로 되어 있기에 x,y 순서로 변경
scaled_coords = [(int(x), int(y)) for y, x in contour]
# 시각화 코드: 폴리곤을 빨간색으로 그리기
x_coords, y_coords = zip(*scaled_coords) # x, y 좌표 분리
plt.plot(x_coords, y_coords, color='r', lw=2) # 빨간색 선으로 윤곽선 시각화
plt.gca().invert_yaxis() # 원점을 왼쪽 상단으로
3. 추출한 polygon을 데이터셋으로 제작
이제 polygon 결과를 txt파일에 저장하기만 하면 됩니다.
os를 통해 파일을 제작하고 해당 파일에 polygon 결과를 넣는 형태로 진행하였습니다.
참고로 yolo의 segmentation dataset의 label은 아래 구조로 이루어져 있습니다.
classID x1 y1 x2 y2 x3 y3 ···
이때 x & y 좌표값은 이미지의 가로 & 세로 길이로 나눠져 있기때문에 이를 유의해서 데이터셋을 제작해야합니다.
결과 코드는 아래와 같습니다
import numpy as np
import torch
import numpy as np
import matplotlib.pyplot as plt
import cv2
import sys
import os
from matplotlib import pyplot as plt
# 시각화를 위한 함수 선언
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30/255, 144/255, 255/255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels==1]
neg_points = coords[labels==0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0,0,0,0), lw=2))
# SAM 모델 Load
sys.path.append("..")
from segment_anything import sam_model_registry, SamPredictor
# pth 파일은 hugging face에서 다운로드 가능합니다
sam_checkpoint = "sam_vit_h_4b8939.pth"
model_type = "vit_h"
device = "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
# 이미지와 label 위치 지정
image_dir = ""
label_dir = ""
# 이미지 파일의 이름 가져오기
image_files = [f for f in os.listdir(image_dir) if f.endswith('.jpg')]
output_dir = ""
# 반복문을 통해 이미지 파일과 label 파일의 정보 SAM에 넣기
for i, image_file in enumerate(image_files):
# 매 이미지 마다 list 초기화
input_boxes = []
image_path = os.path.join(image_dir, image_file)
label_file = os.path.splitext(image_file)[0] + ".txt"
label_path = os.path.join(label_dir, label_file)
output_label_path = os.path.join(output_dir, label_file)
if os.path.exists(label_path):
image = cv2.imread(image_path)
height, width, _ = image.shape
# 각 이미지마다 predictor 설정
predictor.set_image(image)
input_boxes = [] # 이미지마다 새로 초기화
with open(label_path, 'r') as f:
for line in f.readlines():
class_id, x_center, y_center, box_width, box_height = map(float, line.strip().split())
x_center *= width
y_center *= height
box_width *= width
box_height *= height
# Convert to top-left and bottom-right corners (x_min, y_min, x_max, y_max)
x_min = int(x_center - (box_width / 2))
y_min = int(y_center - (box_height / 2))
x_max = int(x_center + (box_width / 2))
y_max = int(y_center + (box_height / 2))
input_boxes.append([class_id, x_min, y_min, x_max, y_max]) # class_id 추가
# 현재 박스의 넓이 계산
area = box_width * box_height
if area < smallest_area:
smallest_area = area
# 텐서로 변환 후 처리
input_boxes_tensor = torch.tensor([box[1:] for box in input_boxes], dtype=torch.float, device='cuda') # class_id 제외하고 박스만 변환
transformed_boxes = predictor.transform.apply_boxes_torch(input_boxes_tensor, image.shape[:2])
masks, _, _ = predictor.predict_torch(
point_coords=None,
point_labels=None,
boxes=transformed_boxes,
multimask_output=False,
)
with open(output_label_path, 'w') as out_file:
for mask, box in zip(masks, input_boxes):
# bool => float
mask_float = mask.cpu().numpy().astype(np.float32)[0]
contours = measure.find_contours(mask_float, 0.5)
for contour in contours:
# 마스크 polygon 좌표 추출
polygon = Polygon([(x, y) for y, x in contour])
# 가장 작은 박스의 1/10 사이즈 보다 작은 mask는 삭제
if polygon.is_valid and polygon.area > smallest_area / 10:
scaled_coords = [(int(x)/mask.shape[2], int(y)/mask.shape[1]) for y, x in contour]
flattened_coords = [coord for point in scaled_coords for coord in point]
# YOLO segmentation 형식으로 파일에 저장
out_file.write(f"{int(box[0])} " + " ".join(map(str, flattened_coords)) + "\n") # class_id 반영
else:
not_found.append(label_path)

결과적으로 위와같이 polygon이 잘 반영되었습니다!!
'ML' 카테고리의 다른 글
| [논문 리뷰] Learning from Rich Semantics and Coarse Locationsfor Long-tailed Object Detection (0) | 2025.01.27 |
|---|---|
| [논문]Deep Learning Based Speed Estimation for Constraining Strapdown Inertial Navigation on Smartphones (1) | 2025.01.21 |
| Precision, Recall에 대해 (0) | 2024.11.30 |
| [논문 리뷰] Visual Prompt Tuning (3) | 2024.09.22 |
| [논문 리뷰]Perceptual Image Enhancement for Smartphone Real-Time Applications (1) | 2024.07.21 |



