기존 ViT는 이미지를 패치 단위로 나누어 해당 패치를 Transformer Encoder에 적용하는 방식으로 동작하게 됩니다.
그런데 기존의 ViT의 경우 Self-Attention 시 계산 복잡도가

다음과 같이 이미지 해상도의 제곱에 비례하여 증가합니다.
그러나 이미지의 경우 픽셀 수가 상당히 많기 때문에 이런 계산 복잡도는 데이터셋의 해상도에 따라 엄청난 차이를 만들 수 있습니다.
이런 문제를 해결하고자 Swin Transformer는 Hierarchical architecture를 통해 다양한 스케일에 유동적이고 선형적 계산 복잡도를 가지도록 제작되었습니다.
- Hierarchical architecture

앞서 언급한 Hierarchical architecture 입니다.
그림과 같이 이미지를 패치 단위로 나누지만 기존의 ViT와는 다른게 패치의 크기가 Layer에 따라 다르며 인접한 패치들이 일정한 크기별로 나눠져 있는 것을 볼 수 있습니다.
- Patch Merging
패치의 크기가 Layer에 따라 다른 것은 본 논문에서 Patch Merging에 의한 결과이며

아래와 같이 Stage가 넘어감에 따라 Merging이 진행됩니다.
Patch Merging은 인접한 patch들을 병합하여, patch 숫자를 줄임으로 계산 복잡도를 줄이고, 동시에 채널 수를 확장합니다.
- W-MSA & SW-MSA (window based multi-head self-attention)
인접한 패치들이 일정한 크기별로 나눠져 있는 것은 Swin Transformer가 window based multi-head self-attention을
진행하기 때문입니다.
window based multi-head self-attention이란 Local window 내에서만 self-attention을 진행하는 것 입니다.
Window에 대한 그림은 아래와 같습니다.

이러한 방법으로 self-attention을 진행하게 됩니다 . 위 내용만 보고는 shifted window attention 이해가 쉽지 않아서
window 내에서만 self-attention을 수행하면
"ViT의 장점인 전체 문맥을 파악하는 능력이 떨어지는 것 아닐까? 그럼 성능도 떨어질 것 같은데?"
라는 생각을 했습니다. 하지만 역시 shifted window는 이런 문제점을 해결하기 위해 (오) shifted window attention 와 같이 window에 포함된 부분을 변경하여 문맥을 보다 잘 파악하도록 하는 내용이 포함되어 있었습니다.
근데 window의 갯수가 늘었으니 연산이 늘어나게 되는건 아닌가? 라는 생각에 대한 해법은 아래와 같습니다.

위 사진과 같이 각 값들을 좌상단으로 이동시킨 후 기존의 윈도우 크기(위 사진에서는 4x4크기) window 내에서
self-attention을 수행하도록 합니다. 그리고 이때 같은 window안의 patch라도 원본 이미지에서 인접한 patch가 아니라면
mask를 씌워 서로 인접한 patch만 연산하도록 구성하였습니다.
mask는 아래와 같이 형성됩니다.

왼쪽 빨간 박스의 patch를 예시로 한다면, 좌상단부터 우하단까지 flatten하여 같은 영역일 경우 O, 아닐 경우 X로 처리하면 최종적으로 오른쪽과 같은 mask 가 형성됩니다.
이러한 W-MSA와 SW-MSA로 구성된 layer는

이런 형태로 Swin Transformer Block을 구성합니다.
window based multi-head self-attention을 통해 계산 복잡도는 아래와 같이 window 크기에 따라 선형적으로 증가하게 됩니다.
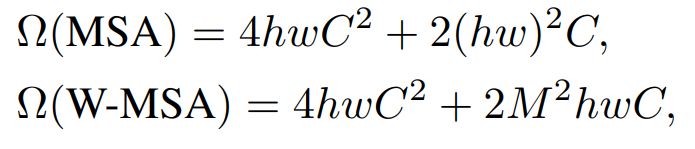
'ML' 카테고리의 다른 글
| [논문 리뷰] MoE-LLaVA (0) | 2025.02.28 |
|---|---|
| [Contrastive Learning]SimCLR 사용하여 학습하기 (0) | 2025.02.23 |
| [논문 리뷰] Learning from Rich Semantics and Coarse Locationsfor Long-tailed Object Detection (0) | 2025.01.27 |
| [논문]Deep Learning Based Speed Estimation for Constraining Strapdown Inertial Navigation on Smartphones (1) | 2025.01.21 |
| Precision, Recall에 대해 (0) | 2024.11.30 |



