MoE-LLaVA는 Meta의 LLM 모델인 Llama를 LVLM 모델로 변환한 LLaVA모델의 parameter를 효율적으로 처리하도록 제작한 모델입니다.
Introduction
LLaVA 또는 MiniGOT-4와 같은 LVLM 모델들이 image encoder 와 여러 visual projection layer들을 통해 LLM 모델을 LVLM모델로 변환하였고 성능 또한 좋은 것을 증명했습니다.
LLM 모델들은 더 많은 데이터와 더 큰 모델 사이즈를 통해 성능을 더욱 더 높여왔습니다.
하지만 각 토큰마다 모든 파라미터를 활성화 하는 기존의 방식으로 인해 엄청난 양의 컴퓨팅 파워가 필요해졌습니다.
이러한 문제를 해결하고자 LLM 분야에서 Mixtures of Experts(MoE) 기법을 활용한 연구가 번창하였으며
좋은 성능을 보여주었습니다.
본 논문은 MoE 기법을 LLaVA에 적용하였고 parameter를 효율적으로 처리하여 높은 성능을 보여주었습니다.
직접적으로 MoE를 LLaVA에 적용하는 시도를 했으나 성능이 엄청나게 떨어지는 것을 발견하여 여러번의 시도 끝에 3단계로 구성된 학습 방법으로 높은 성능을 달성할 수 있었습니다.
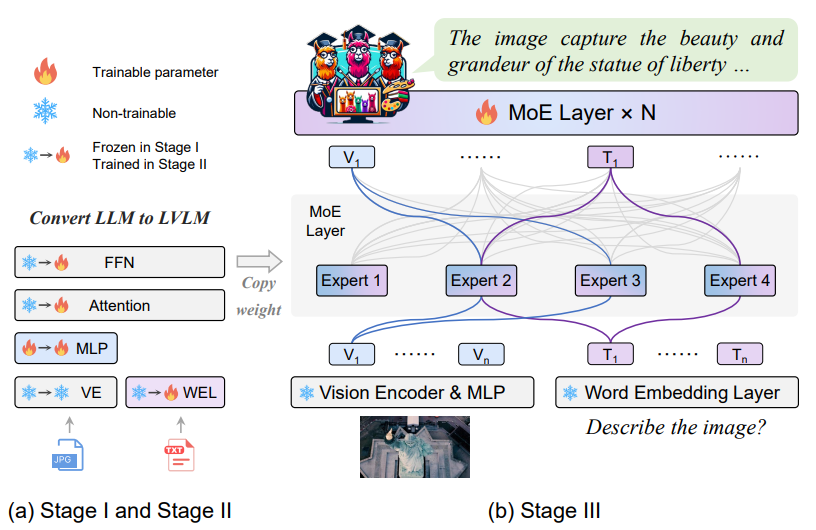
Stage1. Visual token을 LLM에 적용하기 위해 MLP를 학습
Stage2. Multi-modal에 대한 모델의 이해 능력을 늘리기 위해 전체 LLM 파라미터 학습
Stage3. Stage2의 FFN Layer를 복제하여 Expert들의 초기 가중치로 사용하고, MoE Layer와 Router만 학습
Method
이렇게 탄생한 MoE-LLaVA는 Router를 통해 최적의 Expert만 활성화하여 결과를 도출하는 방식으로
Computation Cost를 유지하며 parameter를 확장할 수 있었습니다.
모델의 전체적인 그림은 아래와 같습니다

해당 그림을 수식으로 표현하면

위와 같습니다.
image와 text 토큰이 함께 들어가고 MoE를 사용한다는 것 외에는 다른 모델들과 큰 차이가 있는 것 같지는 않습니다.
본 논문의 핵심인 MoE Layer에 대한 설명입니다

MoE Layer는 Router에서 적절한 k개의 Expert를 선정하여 활성화
하게되는데 해당 방법은 아래 식과 같습니다.

Softmax를 통해 각 토큰에 대한 Expert의 확률을 도출하여 top-k에 해당하는 Expert에 아래 수식을 활용하여

Expert의 출력값과 확률을 가중합 하여 최종 MoE 출력을 도출해냅니다.
MoE-Tuning의 경우 앞서 언급한 Stage2에서 FFN의 weight를 복사하여 Experts로 만들고 학습을 통해 적절한 Expert들을 만드는 형태입니다.
해당 방법에 대해 주관적인 의견이지만 단순히 Weight를 복사하여 해당 값으로 Expert들을 초기화 하고 학습을 통해 적절한 Expert로 만드는 행위가
각 전문가들이 처음에는 같은 weight로 시작한다는 점에서 비효율적이지 않나
는 생각이 들었습니다. 후속연구에 다른 방법이 있는지는 찾아봐야할 것 같습니다.
학습에 사용한 Loss는 아래와 같이 Auto-Regressive Loss 와 Auxiliary Loss 2개입니다.
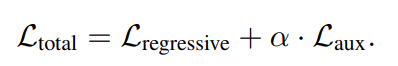
먼저 Auto-Regressive Loss의 경우
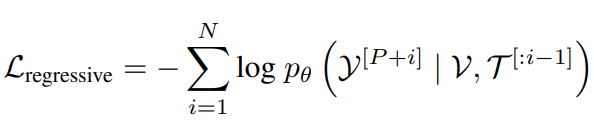
이전 토큰들을 통해 다음 토큰에 대한 확률을 최대화하는 기존의 형태와 같다고 생각됩니다.
Auxiliary Loss는
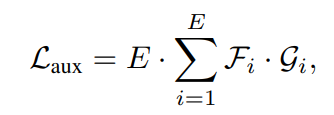
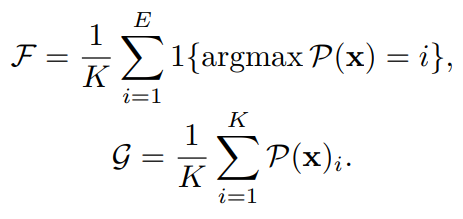
의 형태로 F의 경우 각 Expert가 처리한 토큰의 비율, g는 각 전무가들의 평균 routing 확률로 전체적으로 Expert를 균등하게 사용하기 위한 Loss라고 볼 수 있습니다.
가중치인 α는 본 논문에서 0.01로 설정했으며 실험을 통해 가장 성능이 좋은 값으로 설정했습니다.
Experiments
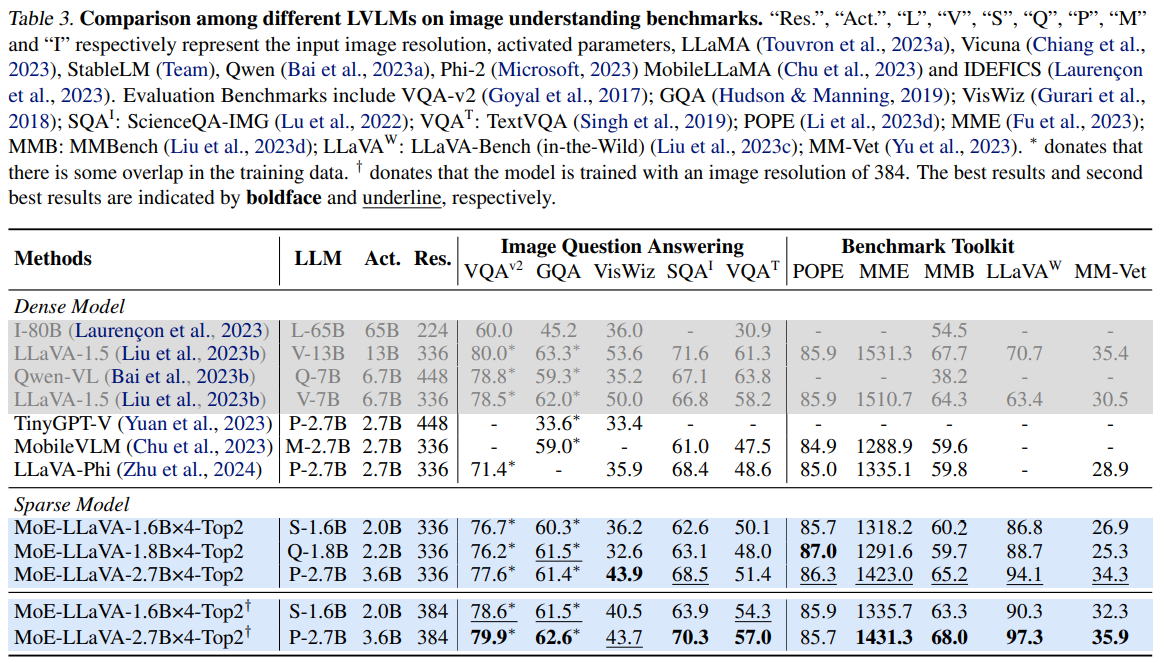
- L: LLaMA (Touvron et al., 2023a)
- V: Vicuna (Chiang et al., 2023)
- S: StableLM (Team)
- Q: Qwen (Bai et al., 2023a)
- P: Phi-2 (Microsoft, 2023)
- M: MobileLLaMA (Chu et al., 2023)
- I: IDEFICS (Laurenc¸on et al., 2023)
회색 부분은 LLM이 상대적으로 큰 모델이며, 파랑 부분은 본 논문에서 제안한 모델입니다.
MoE-LLaVA가 모델의 크기 대비 좋은 성능을 보여주는 것을 볼 수 있습니다.
다음은 Hallucination에 대한 결과입니다
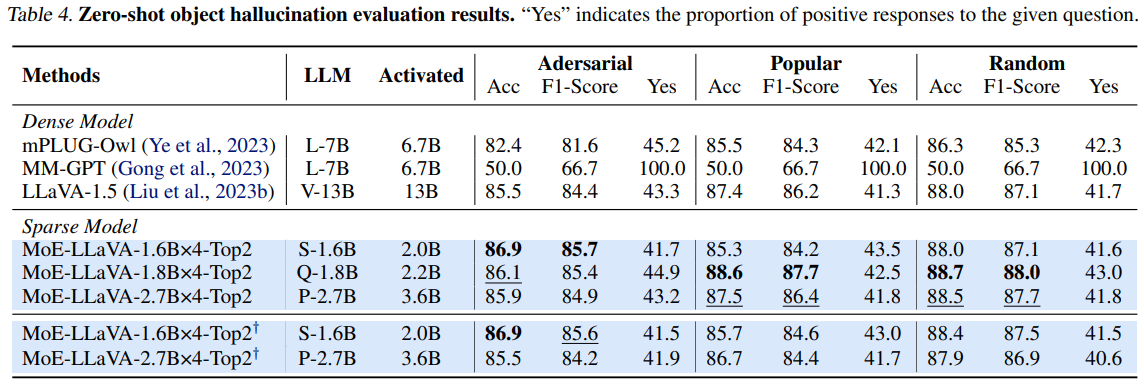
본 논문에서 Hallucination을 평가할때 Polling-based Object Probing Evaluation(POPE) 를 사용하였는데
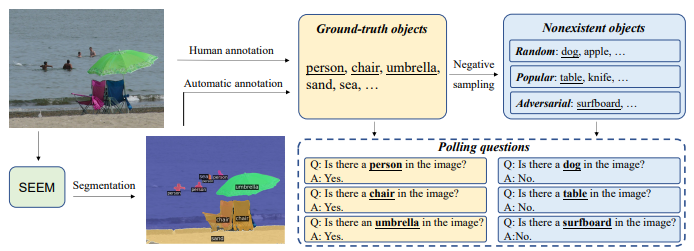
다음과 같이 이미지에서 GT에 존재하는 객체와 존재하지 않는 객체를 Random/Popular/Adversarial
- Random: 전반적인 일반화 성능을 확인
- Popular: 가장 빈번하게 등장하는 유형을 잘 처리하는지 확인
- Adversarial: 모델의 취약점을 드러내거나, 교란을 견디는 능력을 확인
을 기준으로 질문과 그에 따른 대답을 통해 모델을 평가하는 방식입니다.
평가 결과도 MoE-LLaVA가 Hallucination에 강인한 것을 보여줍니다. 다만 결과에서 이미지 Resolution을 더 높여서 학습한 모델의 결과가 더 좋지 않은 이유에 대한 언급이 없어서 아쉬운 것 같습니다.
Conclusion
- Moe-LLaVA는 MoE를 사용하여 효율적인 parameter를 사용하였으며, 그로 인해 높은 정확성 향상에 도달했습니다.
또한 많은 실험을 통해 해당 능력을 입증하였습니다. - 본 논문을 통해 LLM에서 중요한 역할을 하는 기술들을 단순히 LVLM에 적용한다고 성능이 좋아지는 것이 아닌 LVLM에 맞게 tuning이 필요하다는 것을 알게 되었습니다.
- 또한 최근 논문들은 실험을 정말 잘한다는 것을 다시 한번 느끼게 된 것 같습니다.
'ML' 카테고리의 다른 글
| [Contrastive Learning]SimCLR 사용하여 학습하기 (0) | 2025.02.23 |
|---|---|
| [논문]Swin Transformer (1) | 2025.02.10 |
| [논문 리뷰] Learning from Rich Semantics and Coarse Locationsfor Long-tailed Object Detection (0) | 2025.01.27 |
| [논문]Deep Learning Based Speed Estimation for Constraining Strapdown Inertial Navigation on Smartphones (1) | 2025.01.21 |
| Precision, Recall에 대해 (0) | 2024.11.30 |



