1. Intorduction
딥러닝을 활용한 Object detection 모델은 Large-scale datasets(COCO, Open Images)을 통해 많은 성능 향상을 이뤘습니다. 하지만 이러한 학습 결과는 아래와 같이 어두운 이미지에서는 성능이 떨어지는 문제가 있습니다.

이러한 문제를 해결하기 위한 방법으로
- Light-enhanced 이미지를 활용한 학습
- 밝은 이미지에 대한 학습 후 어두운 이미지를 활용한 fine-tuning 방법
이 있습니다. 하지만 이러한 방법은 모두 필수적으로 어두운 이미지가 필요한데 어두운 이미지에 대한 데이터셋은 수집하기 어렵다는 문제가 있습니다.
이런 문제를 피하기 위해 본 논문은 아래 사진과 같이 zero-shot day-night domain adaptation setting을 사용하였습니다.
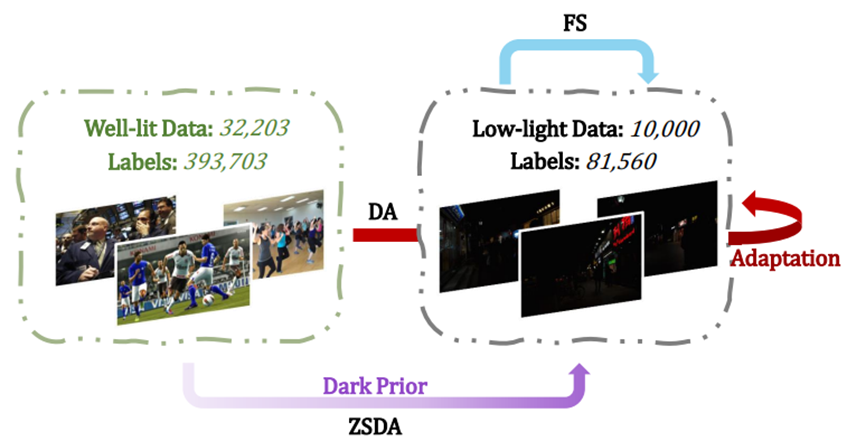
해당 방법은 밝은 이미지 데이터셋 만을 활용한 ZSDA(Zero-Shot Day-night Adaptation) 방법을 통해 학습을 진행합니다.
이를 위해 DArk-Illuminated Network(DAI-Net)를 제안하였습니다.
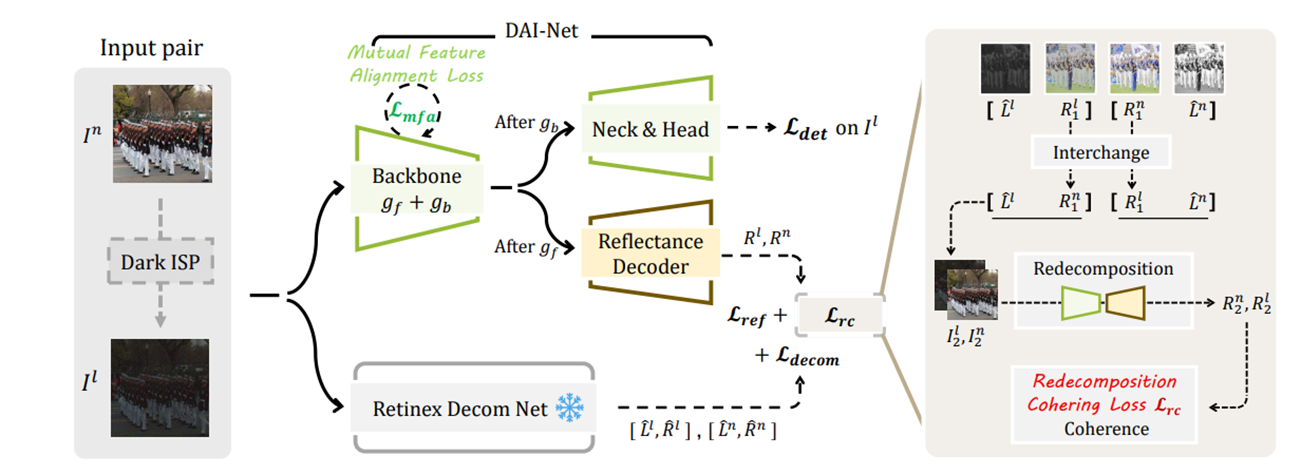
DAI-Net
- low-illumination synthesis pipeline(Dark ISP)를 활용하여 밝은 이미지를 어둡게 만듦
- 잘 학습된 Retinex Decom Net을 사용하여 Pseudo GT 출력
- 어두운 이미지를 Image Refectance와 Image Illumination으로 분리하여 학습에 활용
- Backbone을 이미지의 밝기에 관계없이 비슷한 feature를 출력하도록 학습
- Inference 시 추가적인 모듈 없이 기존 detection 모델만 사용
Contribution
Introduce a reflectance representation learning module
- 밝기 변화에 강인한 반사율을 사용하여 학습하는 모듈을 개발
Propose an interchange-redecomposition-coherence procedure
- Interchange-redecomposition 방식을 통해 image decomposition 방법을 강화
Conduct extensive experiments
- 여러 실험을 통해 기존 모델들 대비 높은 정확성을 보임
(주관) 본 논문을 읽기 전 가장 중요한 부분이라 생각하는 부분은 Retinex Theory와 Reflection이라 생각합니다.
Retinex Theory란 Retina + Cortex 합성어로 인간의 시각과 비슷한 색상 인지 방법을 표현한 이론입니다.
해당 이론의 가정은
- S(image) = R(reflection) · I(illumination)
으로 여기서 reflection은 밝기에 관계없는 고유한 값이라는 가정이 있습니다.
따라서 본 논문은 고유한 값을 가진 reflection을 활용하여 학습을 진행합니다.
2. Proposed method

위 그림과 같이 본 논문은 밝은 이미지에 Dark ISP를 적용하여 어둡게 만든 이미지를 pair로 학습을 진행합니다.
Pair를 Retinex Decom Net의 입력으로 사용하여 각 이미지의 pseudo-GT[ 𝐿̂(illumination), 𝑅̂(Reflection) ]를 출력합니다.
Backbone의 경우 gf(frontal part)와 gb(whole part)로 구분되어 있는데 Image decomposition은 low-level vision task이므로전체 Backbone 중 2번째 conv layer까지를 gf로 설정하였습니다.
gf에서 출력된 feauture를 통해 L_mfa loss를 구하는 데 loss의 수식은 아래와 같습니다.
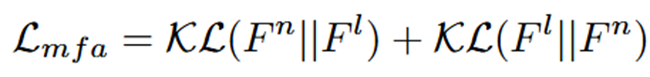
KL-Divergence를 통해 밝은 이미지와 어두운 이미지의 feature 분포가 서로 비슷하게 되도록 만들어 어두운 이미지에서도 적절한 feature를 뽑을 수 있게 제작하였습니다.
(왜 하필 KL-Divergence일까? 라는 의문이 생길 수 있는데 본 논문의 ablation study에서 KL을 사용했을 때의 성능이 가장 좋았으며, L1 or L2 loss의 경우 harsh constraint 즉, 과도한 제약으로 인해 학습이 잘 되지 않았다고 설명했습니다.)
gf이후의 값을 Reflectance Decoder(2개의 Conv+ReLU layer로 구성)에 넣은 후 Reflectance를 출력하게 됩니다.
출력된 Reflectance는 pseudo-GT의 값과 비교하는 아래 loss를 통해 밝기에 독립적인 Reflectance를 학습하게 됩니다.
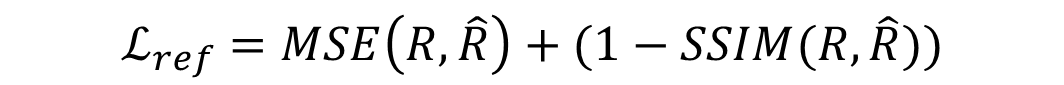
Interchange-Redecomposition-Coherence
앞서 언급했던 것과 같이 본 논문은 image decomposition 방법을 강화하기 위해 해당 방법을 제시하였습니다.
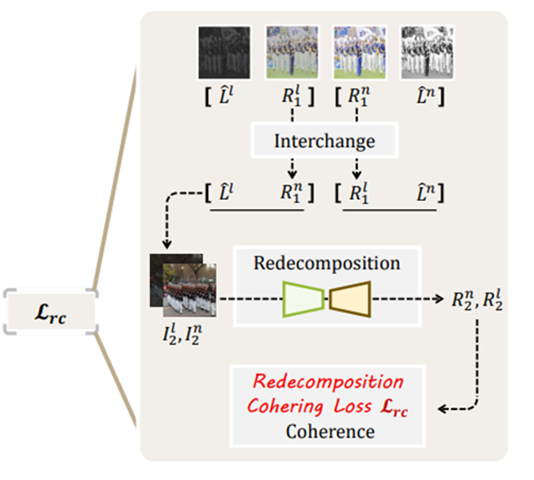
위 그림과 같이 pseudo-GT와 Reflectance Decoder에서 출력한 reflectance를 서로 교환하여 새로운 이미지(I2)를 만들고 해당 이미지를 Redecomposition하여 아래와 같은 redecomposition loss를 계산합니다.

이러한 방법을 통해 독립적인 relectance 학습을 강화하도록 하였습니다.
(주관) Inference 시 사용하지 않는 Reflectance Decoder가 논문의 핵심적인 reflectance를 출력하는 것은 너무 많은 가중을 주는게 아닐까?
Total Loss function
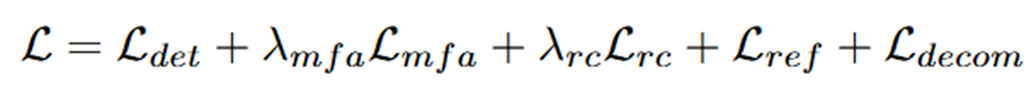
전체 loss는 위 식과 같습니다.
이때 det loss의 경우 적용하는 detection model의 loss를 사용하며, 나머지는 모두 설명하였습니다. 하지만 마지막의 loss인 decomposition loss는 설명하지 않았는데 해당 loss는 아래의 식을 따릅니다.
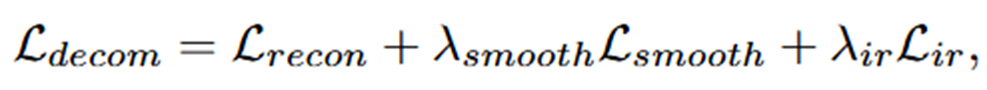
처음 논문을 보고 recon과 smooth에 대한 정확한 식이 없어서 당황했는데 해당 loss는 Retinex Decom Net의 loss를 거의 그대로 사용합니다.
위 논문의 식을 따라 사용한 decom loss의 수식은 아래와 같습니다.

3. Experiments
실험은 총 3가지의 task로 진행하였습니다.
- Face detection
- Object detection
- Image classification
Face Detection
Dataset: WIDER FACE, COCO 2017

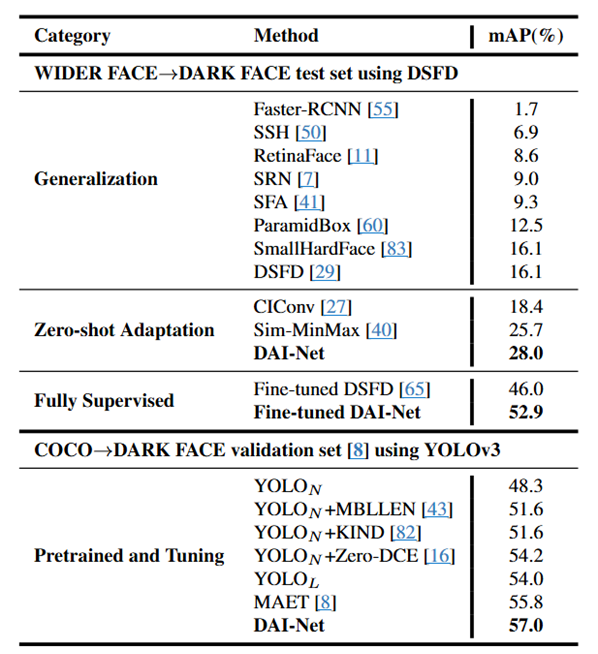
- Generalization: Trained on the source domain and directly evaluated on the target domain
- Zero-shot Adaptation: Compare with ZSDA methods by applying them to DSFD for detection
- Fully Supervised: Fine-tuned in their respective object detection learning manners
- COCO→DARK FACE: compare with MAET using YOLOv3 trained on COCO and finetuned the same way on DARK FACE
위 결과와 같이 DAI-Net이 다른 모델들에 비해 매우 높은 성능을 보였으며, Zero-shot Adaptation 뿐만 아니라 Fine-tuning방식에서도 높은 성능을 보여줍니다.
Object Detection in Darkness
Datasets: ExDark, COCO 2017

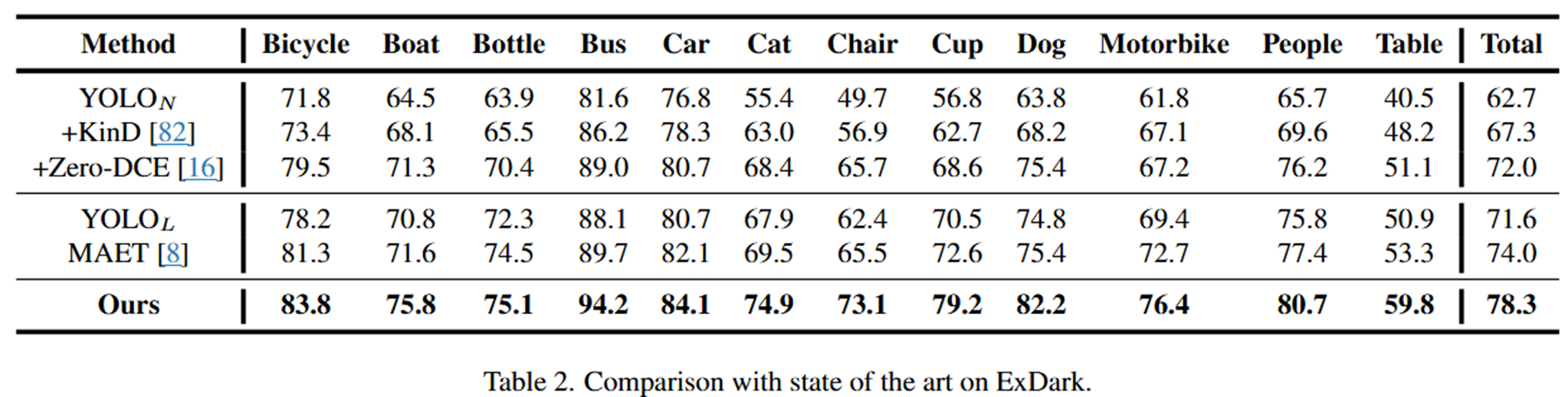
4. Results

최종 결과 사진입니다. 다른 모델들에 비해 본 논문에서 제안한 방법의 정확성이 더 높았으며, scratch 부터 학습 보다는 source domain에서 학습한 후 fine-tuning하는 형태가 더 높은 정확성을 보였습니다.
Comment
본 논문을 통해 어두운 영상과 밝은 영상이 Domain이 서로 다른 영상이라는 것을 알게 되었으며, 실험을 통해 생각보다 단순히 fine-tuning을 진행하는 것도 많은 성능 향상을 가져온다는 것을 알게되었습니다.
또한, 빛의 밝기에 독립적은 Reflection을 활용하는 방법에 대해 좀 더 고민해보고 Reflectance Decoder의 가중치를 줄이면서 전체적으로 성능 향상을 할 수 있는 방법에 대한 연구를 할 예정입니다.
'ML' 카테고리의 다른 글
| [논문] Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Video (1) | 2025.06.02 |
|---|---|
| [논문] MoSAM: Motion-Guided Segment Anything Model with Spatial-TemporalMemory Selection (0) | 2025.05.12 |
| [논문 리뷰] MoE-LLaVA (0) | 2025.02.28 |
| [Contrastive Learning]SimCLR 사용하여 학습하기 (0) | 2025.02.23 |
| [논문]Swin Transformer (1) | 2025.02.10 |



